|
|
|


4 回复 | 直到 17 年前

|
1
2
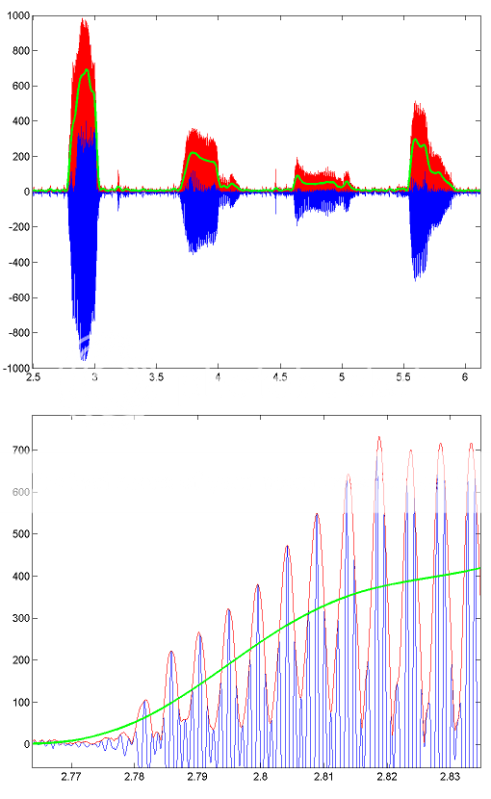
HILBERT , BUTTER ,以及 FILTFILT . smoothData 为了说明这种处理是如何工作的,这里有一些图像显示了录制语音片段的结果。蓝线是原始语音信号,红线是包络(使用HILBERT获得),绿线是低通滤波结果。下图是第一个的放大版本。
然而,根据信噪比的不同,尚不清楚需要重复多少次才能得到你感兴趣的局部最大值。这只是一个随机的非滤波选项。 =) 最大值发现:
|
|
|
2
3
|
|
|
3
1
如果你的数据上下跳很多,那么函数将有许多局部最大值。 所以我假设你不想找到所有的局部最大值。但是,你对当地最大值的标准是什么?如果你有一个标准,那么你可以为此设计一个方案或算法。 我现在想,也许你应该先对数据应用低通滤波器,然后找到局部最大值。尽管滤波后的局部最大值的位置可能与滤波前的位置不完全对应。 |
|
|
4
1
有两种方法可以看待这个问题。人们可以将此视为一个主要的平滑问题,使用滤波工具对数据进行平滑处理,然后使用各种插值方法(可能是插值样条)进行插值。找到插值样条的局部最大值是一件很容易的事情。(请注意,您通常应该在这里使用真样条,而不是pchip插值。当您在interp1中指定“三次”插值时使用的pchip方法,将无法准确定位落在两个数据点之间的局部最小值。) 解决这个问题的另一种方法是我更喜欢的方法。这里使用最小二乘样条模型来平滑数据,并产生近似值而不是插值值。这种最小二乘样条具有允许用户进行大量控制以将他们对问题的知识引入模型的优点。例如,科学家或工程师通常拥有关于所研究过程的信息,如单调性。这可以内置到最小二乘样条模型中。另一个相关的选项是使用平滑样条线。它们也可以通过内置正则化约束来构建。如果你有样条线工具箱,那么spap2将对拟合样条线模型有用。然后fnmin会找到一个最小化器。(最大化器很容易从最小化代码中获得。) 当数据点等距时,采用滤波方法的平滑方案通常最简单。不等间距可能会推动最小二乘样条模型。另一方面,在最小二乘样条曲线中,结点位置可能是一个问题。我的观点是,这两种方法都有其优点,可以产生可行的结果。 |
推荐文章
|
|
SH_IQ · 在MATLAB条形图中为特定条形图颜色添加其他图例 1 年前 |

|
|
Vlad Vadean · Matlab数组乘法 1 年前 |
|
|
Catalin Baba · 如何在MATLAB中连接两个向量 1 年前 |

|
|
servoz · 在matlab和python中创建类似的矩阵对象 2 年前 |
|
|
CircAnalyzer · MATLAB中字符串的十进制数列表 2 年前 |
|
|
I Like Algebra · 在Julia中交换行的最简单方法 2 年前 |