|
|
|


5 回复 | 直到 7 年前

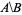{kind=link}

|
2
34
几个月前有人在上海教我怎么做,但我一时找不到…我在看的时候无意中发现了你的问题。这里是: |
|
|
3
4
使用
示例设置我们将使用keepnodes和deletenodes。它们被用作未排序的输入。 默认情况下,comm不带参数打印3列
这是一个赤裸裸的例子
抑制列输出使用-n抑制列1、2或3;请注意,当隐藏列时,空白会缩小。 当你忘记分类的时候,它会优雅地失败。
|
|
|
4
3
例如,您可能只希望在表示非负数的行中找到差异: |
|
|
5
1
也许你需要一个更好的方法在postgres中完成它,我敢打赌你不会找到一个更快的方法来使用平面文件。您应该能够执行一个简单的内部连接,并假设两个id列都被索引,这应该非常快。 |
推荐文章