|
|
|




5 回复 | 直到 9 年前

|
1
5
|

|
2
2
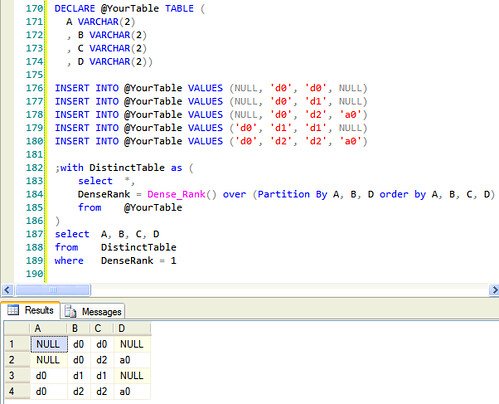
使用
Dense_Rank()
用A、B和D划分
根据 MSDN ,
分区划分
这是结果
代码如下: |
|
|
3
0
可能是子查询? 从存在的表1中选择A、B、C、D(从表1中选择不同的A、B、D); |
|
|
4
0
在a和d中有空的事实说明了任何存在的事物。 C上的任何最小/最大解都不能按我想的那样给您空值。否则,使用min(c)和简单的group by。 您必须先提取唯一键(A、B、D),然后使用该键再次确定提取行,并计算出如何处理C。 |
|
|
5
0
如果您在表中有一个唯一的ID,那么我将使用如下代码: SELECT A,B,C,D FROM table WHERE id IN (SELECT DISTINCT A,B,D) 问题是,你总是会得到C的第一个值,而不是有值的第一个值。 |
推荐文章

|
Johnny T · 基于当前值的SQL合并表[重复] 5 月前 |

|
John D · 需要为NULL或NOT NULL的WHERE子句 5 月前 |

|
ojek · 如何对SQL结果进行分组和编号? 5 月前 |
|
|
senek · 如何在PL/SQL中将选择结果(列)放入数组中 5 月前 |
|
|
Sax · 规范化Google表格(第一步) 5 月前 |
|
|
Jatin · 检索卷计数的动态sql抛出错误语法错误[关闭] 5 月前 |
|
|
Andrus · 如何在sql中查找第二个匹配项 6 月前 |